Zero-Shot Everything Sketch-Based Image Retrieval,
and in Explainable Style
Fengyin Lin1* Mingkang Li1* Da Li2† Timothy Hospedales2,3 Yi-Zhe Song4 Yonggang Qi1
1Beijing University of Posts and Telecommunications
2Samsung AI Centre, Cambridge
3University of Edinburgh
4SketchX, CVSSP, University of Surrey
CVPR 2023
 arXiv
arXiv Dataset
Dataset Code
Code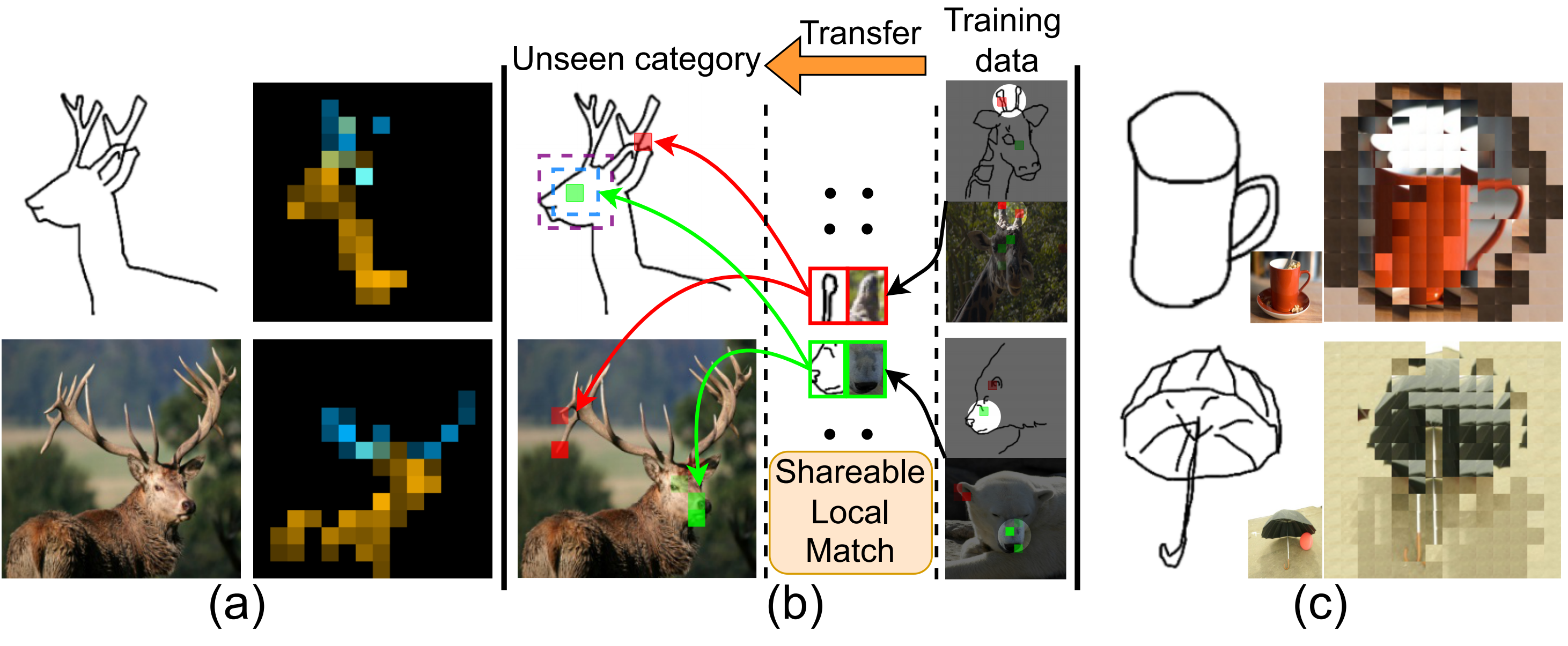
Figure 1. Attentive regions of self-/cross-attention and the learned visual correspondence for tackling unseen cases. (a) The proposed retrieval token [Ret] can attend to informative regions. Different colors are attention maps from different heads. (b) Cross-attention offers explainability by explicitly constructing local visual correspondence. The local matches learned from training data are shareable knowledge, which enables ZS-SBIR to work under diverse settings (inter- / intra-category and cross datasets) with just one model. (c) An input sketch can be transformed into its image by the learned correspondence, i.e., sketch patches are replaced by the closest image patches from the retrieved image.
Introduction
This paper studies the problem of zero-short sketch-based image retrieval (ZS-SBIR), however with two significant differentiators to prior art
(i) we tackle all variants (inter-category, intra-category, and cross datasets) of ZS-SBIR with just one network ("everything"), and
(ii) we would really like to understand how this sketch-photo matching operates ("explainable").
Our key innovation lies with the realization that such a cross-modal matching problem could be reduced to comparisons of groups of key local patches - akin to the seasoned "bag-of-words" paradigm.
Just with this change, we are able to achieve both of the aforementioned goals, with the added benefit of no longer requiring external semantic knowledge.
Technically, ours is a transformer-based cross-modal network, with three novel components
(i) a self-attention module with a learnable tokenizer to produce visual tokens that correspond to the most informative local regions,
(ii) a cross-attention module to compute local correspondences between the visual tokens across two modalities, and finally
(iii) a kernel-based relation network to assemble local putative matches and produce an overall similarity metric for a sketch-photo pair.
Experiments show ours indeed delivers superior performances across all ZS-SBIR settings. The all important explainable goal is elegantly achieved by
visualizing cross-modal token correspondences, and for the first time, via sketch to photo synthesis by universal replacement of all matched photo patches.
Our Solution
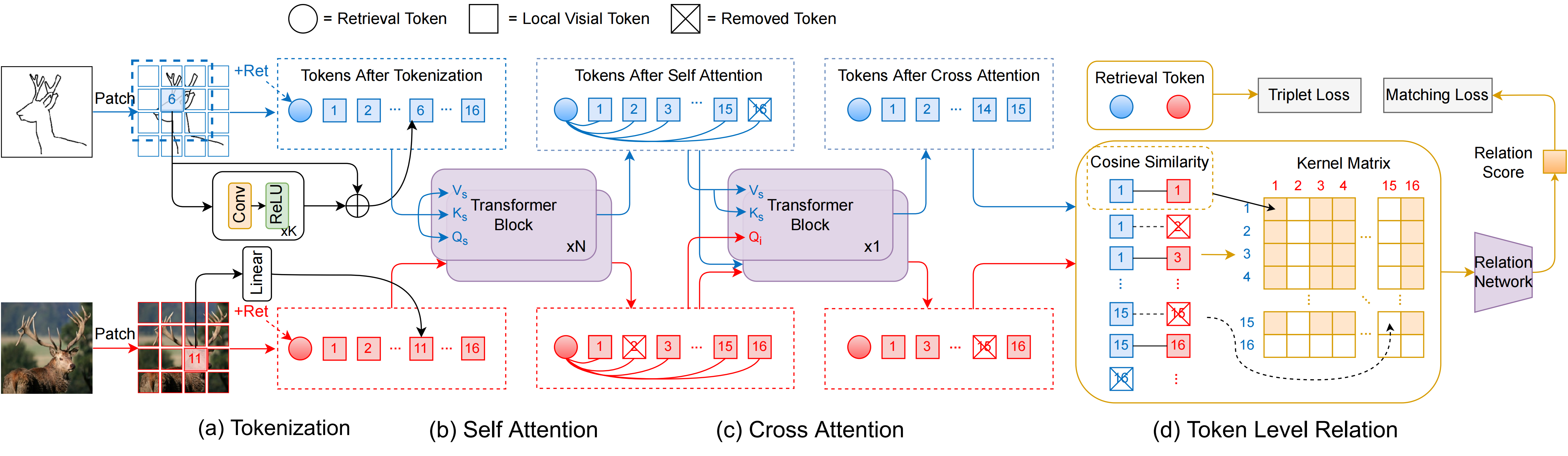
Figure 2. Network overview.
As shown in Figure 2, (a) Learnable tokenization generates structure preserved tokens, preventing the generation of uninformative tokens. (b) Self-attention finds the most informative regions ready for local matching. (c) Cross-attention learns visual correspondence from visual tokens. A retrieval token [Ret] is added as a supervision signal during training. (d) Token-level relation network enables to explicitly measure the correspondences of cross-modal token pairs. Pairs of removed tokens as per token selection will not be counted.
Experiments and Results
Category-level ZS-SBIR
| Method | ESI | RD | TU-Berlin Ext | Sketchy Ext | Sketchy Ext Split | QuickDraw Ext | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| mAP | Prec@100 | mAP | Prec@100 | mAP@200 | Prec@200 | mAP | Prec@200 | |||
| ZSIH | √ | 64 | 0.220 | 0.291 | 0.254 | 0.340 | - | - | - | - |
| CC-DG | ✗ | 256 | 0.247 | 0.392 | 0.311 | 0.468 | - | - | - | - |
| DOODLE | √ | 256 | 0.109 | - | 0.369 | - | - | - | 0.075 | 0.068 |
| SEM-PCYC | √ | 64 | 0.297 | 0.426 | 0.349 | 0.463 | - | - | - | - |
| SAKE | √ | 512 | 0.475 | 0.599 | 0.547 | 0.692 | 0.497 | 0.598 | 0.130 | 0.179 |
| SketchGCN | √ | 300 | 0.324 | 0.505 | 0.382 | 0.538 | - | - | - | - |
| StyleGuide | ✗ | 200 | 0.254 | 0.355 | 0.376 | 0.484 | 0.358 | 0.400 | - | - |
| PDFD | √ | 512 | 0.483 | 0.600 | 0.661 | 0.781 | - | - | - | - |
| ViT-Vis | ✗ | 512 | 0.360 | 0.503 | 0.410 | 0.569 | 0.403 | 0.512 | 0.101 | 0.113 |
| ViT-Ret | ✗ | 512 | 0.438 | 0.578 | 0.483 | 0.637 | 0.416 | 0.522 | 0.115 | 0.127 |
| ViT-Ret | ✗ | 512 | 0.438 | 0.578 | 0.483 | 0.637 | 0.416 | 0.522 | 0.115 | 0.127 |
| DSN | √ | 512 | 0.484 | 0.591 | 0.583 | 0.704 | - | - | - | - |
| BDA-SketRet | √ | 128 | 0.375 | 0.504 | 0.437 | 0.514 | 0.556 | 0.458 | 0.154 | 0.355 |
| SBTKNet | √ | 512 | 0.480 | 0.608 | 0.553 | 0.698 | 0.502 | 0.596 | - | - |
| Sketch3T | √ | 512 | 0.507 | - | 0.575 | - | - | - | - | - |
| TVT | √ | 384 | 0.484 | 0.662 | 0.648 | 0.796 | 0.531 | 0.618 | 0.149 | 0.293 |
| Ours-RN | ✗ | 512 | 0.542 | 0.657 | 0.698 | 0.797 | 0.525 | 0.624 | 0.145 | 0.216 |
| Ours-Ret | ✗ | 512 | 0.569 | 0.637 | 0.736 | 0.808 | 0.504 | 0.602 | 0.142 | 0.202 |
Table 1. Category-level ZS-SBIR comparison results. “ESI” : External Semantic Information. “-” : not reported. The best and second best scores are color-coded in red and blue.
Bibtex
If this work is useful for you, please cite it:
@inproceedings{zse-sbir-cvpr2023,
title={Zero-Shot Everything Sketch-Based Image Retrieval, and in Explainable Style},
author={Fengyin Lin, Mingkang Li, Da Li, Timothy Hospedales, Yi-Zhe Song and Yonggang Qi},
booktitle={IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2023}
}
Created by Fengyin Lin @ BUPT
2023.5